In our fast urbanising world, an estimated 4.2 billion people live in cities. Although those of us who live in cities are generally wealthier and healthier than those living in rural areas, in large cities like London the rich and the poor end up living side by side in very different conditions. These different living conditions determine people’s quality of life and health and are at the root of social inequalities, which are very difficult to tackle. But before we can even think of policy solutions to address these issues, how can we understand the problem?
Traditionally, data on health, income, wellbeing, and employment come from national surveys and censuses that are expensive, labour intensive, and typically carried out every 5 or 10 years. In addition, in low- and middle-income countries national data may be sparse or even lacking completely. Emerging sources of large-scale data, such as street-level imagery, have the potential to fill these gaps and provide data more frequently, conveniently and with greater precision than traditional methods. These data can then be analysed and mapped to identify areas of intervention.
The idea of mapping inequalities is not novel. The very first map of social inequalities was produced at the end of the 19th century in London by an eminent researcher of that time, Charles Booth. Booth had become very concerned about the increasing presence of poverty and was sceptical of existing government statistics so he decided to embark on a massive project mapping each street in the city to indicate different levels of poverty and wealth. His survey method was very simple, visiting neighbourhoods in person and collecting visual data on homes and residents on a notepad, but it had a flaw: it took him 27 years to complete.
Now in 2019, with a plethora of available street images collected by companies (e.g. Google, Baidu, Mapillary) and cities (e.g. London CCTV), there is the opportunity to reduce the labour of sending individual teams to visit each location. Also, recent developments in artificial intelligence such as deep learning provide us with sophisticated methods to analyse these data and answer questions on how poverty and other social indicators are distributed across cities.
In our work, we wanted to answer the following questions: is it possible to use street view images combined with deep learning methods to measure inequalities in London? How can we compare the performance of these methods to measure outcomes of interest (e.g. living environment, income, housing quality, crime)? And, can a model trained in London be used in other cities?
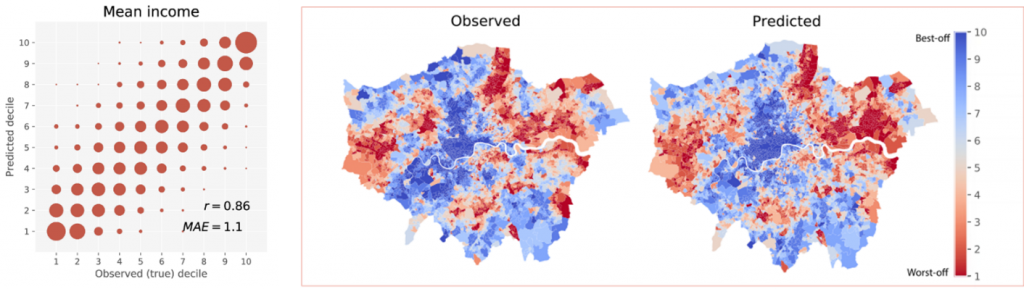
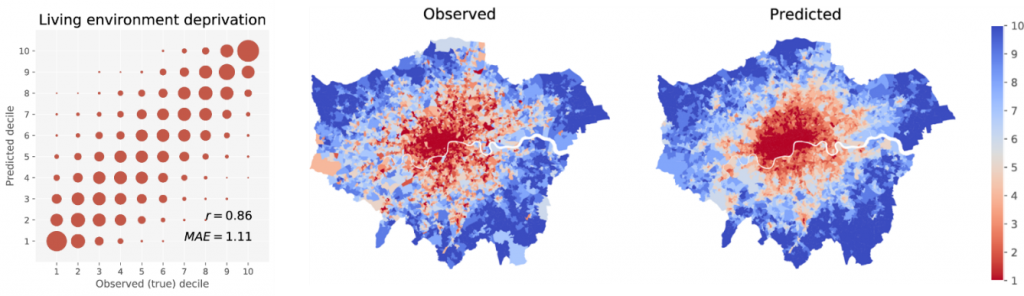
We collected 525,860 Google street view images from 156,581 postcodes covering Greater London and identified a set of survey variables from the census to be of interest e.g. overcrowding, living environment, income, education etc. We hypothesised that these outcomes would have physical correlates that would manifest themselves as visually detectable in the images and would therefore be quantifiable, so we trained a deep learning model letting it identify patterns by itself without manually identifying any specific features.
When we compared the model prediction versus the actual data, we found that the model was very efficient in measuring outcomes like living environment deprivation and income but not others like crime and self-reported health. This might be related to the first two measures having direct visual signs (signs of housing disrepairs, types of cars in the street, shops, plants etc.) while crime and health are more difficult to identify visually.
In order to address the question of transferability, we wanted to test if our model trained on London data was transferable to other cities, in particular Birmingham, Manchester, and Leeds. We achieved good measurement performances in all three cities and were able to decrease the mean absolute error by 23% with only 1% of local data, achieving performances similar to using 100% of local data.
The ability to transfer learned features across cities is an exciting result that opens a range of possibilities for future research without the need for expensive surveys/censuses, especially if combined with other sources of large-scale data such as satellite data, mobile phones, and various forms of crowd-sourced data. In the future, this will allow us to generate reliable and timely data to inform and measure the impacts of urban policies in cities around the world.